
Olá, pessoal. Em publicações anteriores eu falei um pouco sobre a Teoria Clássica dos Testes (TCT) com o intuito de dar uma visão geral sobre o funcionamento dessa poderosa ferramenta estatística e como ela pode ser usada para interpretar testes e avaliações de modo eficiente. Dando continuidade ao tema, como prometido, hoje pretendo falar um pouco sobre a TRI – Teria de Resposta ao Item.
Assim como na TCT, pretendo fazer aqui uma análise mais analítica possível (para que possam compreender a ferramenta e como usá-la) sem adentrar muito no preciosismo matemático para evitar que o texto fique muito técnico. Caso queiram se aprofundar mais na complexidade matemática da coisa vou deixar no final do texto as referências que usei linkadas.
De modo geral, a TRI, segundo alguns autores, é um conjunto de ferramentas e modelos matemáticos que visa mensurar variáveis latentes como a inteligência ou grau de proficiência em determinada área do conhecimento a partir de uma análise individual de cada item do teste através de uma medição indireta. Ela surgiu em meados da década de 1950 para sanar alguns problemas apresentados pela TCT, mas se popularizou a partir da década de 1980, com o avanço da computação e desenvolvimento de softwares apropriados para lidar com a complexidade matemática envolvida na estimação de seus parâmetros.
As principais críticas à TCT envolvem 3 fatores: a) A análise e interpretação dos itens está relacionada a prova como um todo, assim o a qualidade discriminante do item e seu índice de dificuldade dependem do desempenho dos alunos no teste de modo geral, b) o resultado é expresso por um escore bruto (acertos vs erros), ou seja, dois alunos que acertaram 4 questões em um teste com 10 questões teriam, teoricamente, a mesma nota, independentemente de quais seriam as questões, sua dificuldade individual e fator de discriminação. E c) A nota dos alunos só pode ser comparada com a de outros que fizeram exatamente o mesmo teste, ou seja, cada teste cria uma escala de escore própria. Assim, alunos sujeitos a testes diferentes não podem ser comparados entre si, de modo que, em avaliações diferentes, é possível ter provas com dificuldades diferentes. Se pensar nisso para uma avaliação nacional anual (como o ENEM) podemos imaginar uma série de problemas, como estudantes entrando com recursos porque no ano deles a prova (ENEM) foi mais difícil que no ano anterior ou seguinte.

A TRI, como é construída e utilizada, busca resolver principalmente esses problemas uma vez que a) cada item é interpretado unicamente, assim sua dificuldade e discriminação não depende de nenhum outro item ou teste geral, permitindo inclusive a criação de um banco de itens individuais. B) O resultado/proficiência do respondente é baseado em um modelo estatístico que discrimina item a item a partir de seus parâmetros, assim dois alunos que acertaram 6 itens em um teste com 10 questões, não necessariamente terão a mesma nota, uma vez que cada item avalia uma habilidade, conhecimento e tem sua própria dificuldade e fator latente. E c) os itens são calibrados para uma escala comum de modo que é possível garantir (com certa razoabilidade) uma constância no nível de dificuldades e nas habilidades latentes avaliadas em diferentes provas.
Por estes motivos, a TRI é usada amplamente ao redor do mundo e tem vasta literatura da Psicometria acerca de suas bases matemáticas (sugestões no fim). Os principais testes que fazem uso da TRI são os internacionais TOEFL (o Test of English as a Foreign Language) e PISA (Programme for International Student Assessment), e os brasileiros SAEB (Sistema Nacional de Ensino Básico), ENCEJA (Exame Nacional para Certificação de Competências de Jovens e Adultos), SAERSP (o Sistema de Avaliação de Rendimento Escolar do Estado de São Paulo) e o ENEM (Exame Nacional do Ensino Médio).
Bom, mas como funciona a TRI? A primeira coisa que precisamos saber sobre ela são os dois pressupostos da versão que vamos tratar aqui, que são a unidimensionalidade e a independência local.
A unidimensionalidade é a ideia de que apenas UMA habilidade é avaliada nos itens da prova. É claro que há diversas habilidades que afetam o desempenho do respondente (capacidade de interpretar um texto, abstração, síntese de ideias), mas esse pressuposto assume que há uma habilidade dominante responsável pelo bom desempenho no teste.
A independência local assume que, para uma dada habilidade, as respostas a diferentes itens da prova são independentes. Ou seja, um item não depende do outro para ser respondido. Estes dois pressupostos são axiomas e, portanto, não podem ser demonstrados logicamente, são apenas aceitos. Existem ferramentas matemáticas que permitem analisar e verificar a unidimensionalidade e independência local de um item e falaremos mais sobre isso na parte II dessa publicação.
A partir desses pressupostos, podemos definir a TRI como um conjunto de ferramentas estatísticas que permitem relacionar a probabilidade de um aluno acertar um item com sua proficiência em relação as características/habilidades do item. Dentro dessa definição podemos ter diferentes modelos de TRI e aqui vou falar dos mais comuns que são os modelos logísticos de 1, 2 ou 3 parâmetros (esse último usado no ENEM e nas principais provas e testes que citei acima).
Nos 3 modelos o que a TRI fornece, a partir de uma complexa análise, é uma curva, chamada Curva característica do Item (CCI) para cada item/questão. Essa curva representa a relação entre a probabilidade P(θ) de um indivíduo com habilidade θ acertar o item. Assim, um bom item tem uma curva similar a CCI representada abaixo.
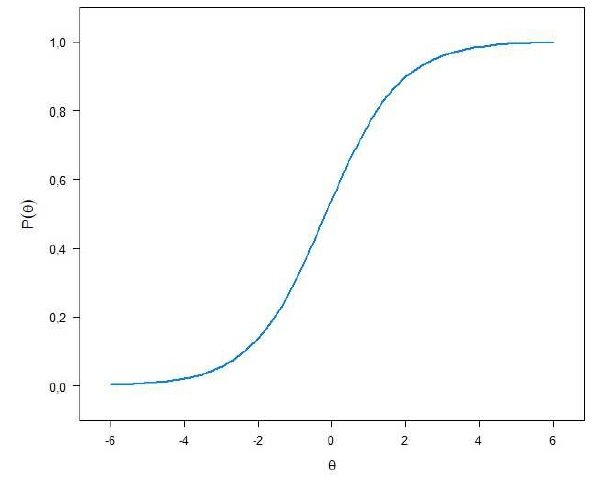
Note que o formato em S implica que quanto maior a habilidade θ do indivíduo (valores de θ subindo para 2, 4 ou 6 em diante) a probabilidade de ele acertar o item se aproxima de 1 (100% de chance de acerto). Enquanto que quanto menor a habilidade θ do indivíduo (valores de θ descendo para – 2, – 4 ou – 6 em diante) a probabilidade do respondente acertar se aproxima de 0.
Modelo logístico de 1 parâmetro:
Neste modelo, o único parâmetro usado para diferenciar os itens de um teste é a dificuldade do item chamado de parâmetro b. Dentro desse modelo, na CCI o parâmetro de dificuldade é o valor de habilidade θ que faz com que a probabilidade de acerto P(θ) seja igual a 0,5 (ou seja 50%). Para exemplificar considere a figura a seguir com dois itens de um teste.
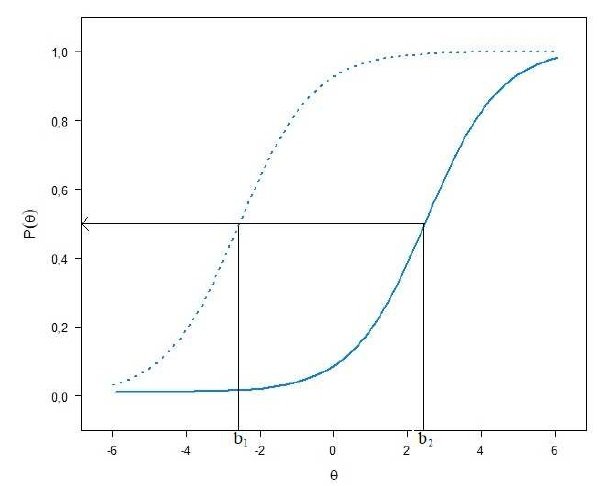
Observe que o item representado pela curva tracejada tem uma dificuldade menor que o item representado pela curva contínua. Isso porque para o item da curva tracejada é necessário uma habilidade menor (b1) para se ter 50% de probabilidade de acertar o item.

A tabela ao lado apresenta uma classificação comum da dificuldade de itens a partir dos valores do parâmetro TRI b.
A terceira coluna (% esperado) representa a porcentagem de questões da prova que devem ter aquele nível de dificuldade.
Modelo logístico de 2 parâmetros:
Neste modelo, além do parâmetro de dificuldade b (descrito acima) é também usado o parâmetro de discriminação “a” que determina a capacidade do item em diferenciar pessoas com diferentes habilidades. Na CCI este item representa a inclinação da curva “S” no momento da inflexão.

Este parâmetro pode assumir qualquer valor em teoria, mas na prática costuma ficar entre – 4 e 4, sendo que valores negativos representam uma inclinação invertida, ou seja, os indivíduos com menor habilidade têm maior probabilidade de acertar o item do que indevidos com maior habilidade. Isso seria um indicativo de erro no gabarito ou questão mal formulada.
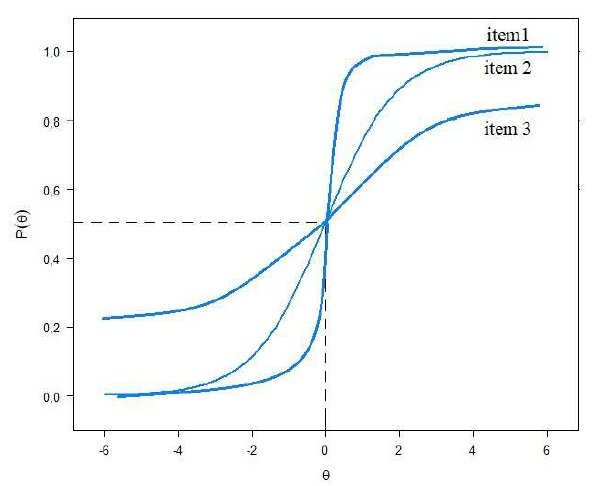

Analisando a acima abaixo com 3 itens com mesma dificuldade (b = 0), vemos que o item 1 discrimina/separa melhor indivíduos com mais ou menos habilidades do que o item 2 e 3, sendo o último o menos discriminativo.
A tabela ao lado indica os principais valores para o parâmetro a e sua capacidade discriminativa.
Modelo logístico de 3 parâmetros:
Este é o modelo mais completo, complexo e usado nos principais exames nacionais e internacionais que fazem uso da TRI. Nele, além dos dois parâmetros citados anteriores (a e b), a análise conta com um terceiro parâmetro “c” que avalia a probabilidade de o respondente acertar o item ao acaso, ou seja, sem ter a habilidade necessária. Em outras palavras, este item avalia a probabilidade de acerto por “chute”.

Analisando a curva vemos que esse parâmetro basicamente estima a probabilidade de acerto de alguém com pouquíssima habilidade (θ muito negativo). Para um item com 5 alternativas (A, B, C, D e E) espera-se que o valor de “c” seja inferior a 0,2. Valores muito superior a 0,2 podem indicar elevado índice de acerto de pessoas com pouca habilidade, sugerindo que a opção correta desta está se diferenciando muito dos demais distratores, atraindo atenção dos estudantes com baixo desempenho.
O post já está um pouco grande e por isso vou encerrando por aqui. Nessa publicação cobri basicamente o que é a TRI e seus principais parâmetros a partir da CCI. Na próxima semana pretendo falar um pouco sobre como é gerada a CCI para um dado item/questão, quais ferramentas podem ser utilizadas para isso e apresentar algumas questões para comparação e análise. Como sempre espero ter ajudado e até a próxima semana.
REFERÊNCIAS:
Dissertação de Mestrado: Teoria clássica dos testes e teoria de resposta ao item aplicadas em uma avaliação de matemática básica – 2018
Dissertação de Mestrado: Análise da dimensionalidade e modelagem multimensional pela TRI no antigo ENEM
Artigo: Classical Test Theory & Item Response Theory
Muito legal, parabéns!
Obrigado!
Sou a Marina Almeida, gostei muito do seu artigo tem
muito conteúdo de valor parabéns nota 10 gostei muito.